

Fotos enthalten nicht immer nur Bilder und Erinnerungen, sondern manchmal auch harte Daten: Texte, Zahlen in Tabellen und vieles mehr. Diese könnt ihr mühsam abtippen oder smart per OCR-Technologie in bearbeitbare Formate umwandeln. Mit modernen KI-Tools geht das heute schneller und präziser denn je!
Am Ende ist ein fotografierter Text nichts anderes als eine Abbildung der Buchstaben in einem Pixelbrei. Genau das lässt sich per Software wieder zurückverwandeln. OCR, Optical Character Recognition (optische Zeichenerkennung) ist der Begriff dafür. Was früher mühsam und fehleranfällig war, funktioniert heute dank KI-gestützter Algorithmen verblüffend zuverlässig.
Moderne OCR-Lösungen: Von kostenlos bis professionell
Für Windows-Nutzer ist FreeOCR nach wie vor eine solide kostenlose Option. Ladet die Software herunter und stellt vor der ersten Nutzung unter OCR-Language die Sprache des Dokuments ein. Bei deutschen Texten mit der Einstellung auf eng für Englisch werden Umlaute nicht erkannt und manche Wörter falsch interpretiert.
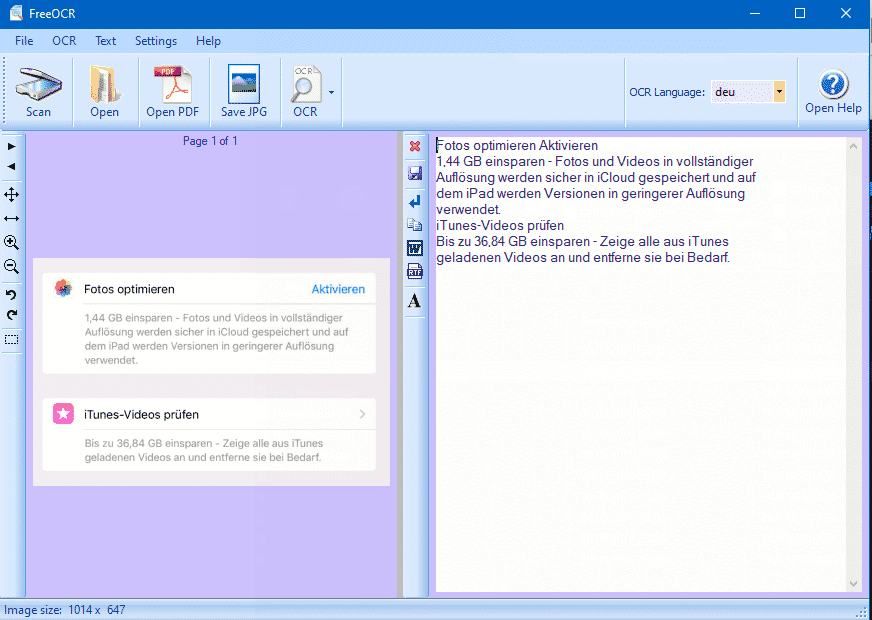
Bei einem Papierdokument mit verfügbarem Scanner klickt ihr auf Scan und scannt das Dokument ein. Bei vorhandenen Fotos klickt ihr auf Open und wählt die Datei aus. Der OCR-Button startet die Texterkennung. FreeOCR durchsucht die Datei nach Buchstaben und gleicht diese mit einer Wortdatenbank ab. Das Ergebnis könnt ihr in die Zwischenablage kopieren oder als Word- oder RTF-Dokument speichern.
KI-Power für bessere Ergebnisse
Moderne OCR-Tools nutzen Machine Learning und erzielen deutlich bessere Resultate. Microsoft PowerToys Text Extractor ist kostenlos und per Windows-Key + Shift + T aktivierbar. Einfach den Bereich auf dem Bildschirm markieren – fertig ist der extrahierte Text.
Adobe Acrobat Pro DC bietet professionelle OCR-Funktionen mit KI-Unterstützung. PDFs werden automatisch durchsuchbar gemacht, auch bei schlechter Bildqualität. Die Texterkennung funktioniert in über 40 Sprachen und erkennt sogar handschriftliche Notizen.
ABBYY FineReader 16 gilt als Goldstandard für OCR. Die Software erkennt komplexe Layouts, Tabellen und sogar Formeln. Besonders stark bei mehrspaltigen Dokumenten und wissenschaftlichen Texten. Kostet allerdings mehrere hundert Euro.
Smartphone-Apps: OCR für unterwegs
Microsoft Lens (iOS/Android) ist kostenlos und erkennt Text in Echtzeit. Dokumente werden automatisch begradigt und optimiert. Der erkannte Text lässt sich direkt in Word oder OneNote übertragen.
CamScanner kombiniert Scan-Funktionen mit OCR. Die App erkennt Visitenkarten, Belege und Dokumente. Premium-Version bietet erweiterte Bearbeitungsfunktionen und Cloud-Sync.
Google Lens ist in die Kamera-App vieler Android-Phones integriert. Richtet die Kamera auf Text und tippt auf das Lens-Symbol. Der erkannte Text wird markiert und kann kopiert oder übersetzt werden.
Browser-basierte OCR-Tools
Für schnelle Aktionen ohne Software-Installation gibt es webbasierte Lösungen. OnlineOCR.net verarbeitet Bilder bis 15MB kostenlos in über 40 Sprachen. SmallPDF bietet OCR für PDFs direkt im Browser.
Google Drive hat OCR-Funktionen integriert. Ladet ein Bild hoch, öffnet es mit Google Docs – der erkannte Text erscheint unter dem Originalbild.
Tipps für bessere OCR-Ergebnisse
Gute Lichtverhältnisse sind entscheidend. Vermeidet Schatten und Reflexionen. Haltet die Kamera parallel zum Dokument, um Verzerrungen zu minimieren. Höhere Auflösungen verbessern die Erkennungsrate, besonders bei kleinen Schriften.
Kontrast ist euer Freund: Schwarzer Text auf weißem Grund funktioniert am besten. Bei bunten Hintergründen oder Wasserzeichen sinkt die Erkennungsrate drastisch.
Bei mehrsprachigen Dokumenten stellt die richtige Sprache ein. Viele Tools erkennen die Sprache automatisch, aber manuelle Einstellung ist meist präziser.
Datenschutz bei OCR-Tools
Achtung bei webbasierten OCR-Diensten: Eure Dokumente werden auf fremde Server hochgeladen. Bei sensiblen Inhalten nutzt lokale Software oder überprüft die Datenschutzrichtlinien genau.
Microsoft und Google verarbeiten hochgeladene Dokumente auf ihren Servern, aber mit klaren Datenschutzrichtlinien. ABBYY und FreeOCR arbeiten komplett offline.
Für Unternehmen gibt es spezialisierte Lösungen mit On-Premise-Installation und DSGVO-Konformität.
Die Zukunft der Texterkennung
KI-basierte OCR wird immer präziser. Neue Modelle erkennen handschriftliche Texte, verstehen Kontext und korrigieren automatisch Tippfehler. ChatGPT und ähnliche Modelle können bereits Bilder analysieren und Texte extrahieren.
Augmented Reality erweitert OCR um Live-Übersetzungen. Google Translate zeigt übersetzte Texte in Echtzeit über das Kamerabild. Praktisch für Reisen oder fremdsprachige Dokumente.
Die Kombination aus OCR und Large Language Models ermöglicht intelligente Dokumentenanalyse: Nicht nur Text extrahieren, sondern auch zusammenfassen, kategorisieren und weiterverarbeiten.
Zuletzt aktualisiert am 24.02.2026



