
Copyright auf das eigene Gesicht: Dänemarks radikaler Deepfake-Plan
Dänemark will ein Copyright auf das eigene Gesicht, den eigenen Körper und die eigene Stimme einführen – wegen KI
Dänemark will ein Copyright auf das eigene Gesicht, den eigenen Körper und die eigene Stimme einführen – wegen KI

tell dir vor, du hörst die Stimme deines Lieblingsstars – aber es ist nicht wirklich seine Stimme. KI macht’s möglich.

Hollywood-Star Scarlett Johanssen beklagt sich: OpenAIs ChatGPT 4o würde in der App eine Stimme namens „Sky“ verwenden, die ihrer Stimme extrem ähnelt. Ein Streit ist entbrannt.
Microsoft fügt seinem Edge-Webbrowser in Windows 10 viele interessante neue Funktionen hinzu. Eine der neuen Funktionen ermöglicht es, Websites, PDFs und eBooks vorzulesen. So lässt sich die Funktion „Vorlesen“ in Microsoft Edge finden, verwenden und anpassen.
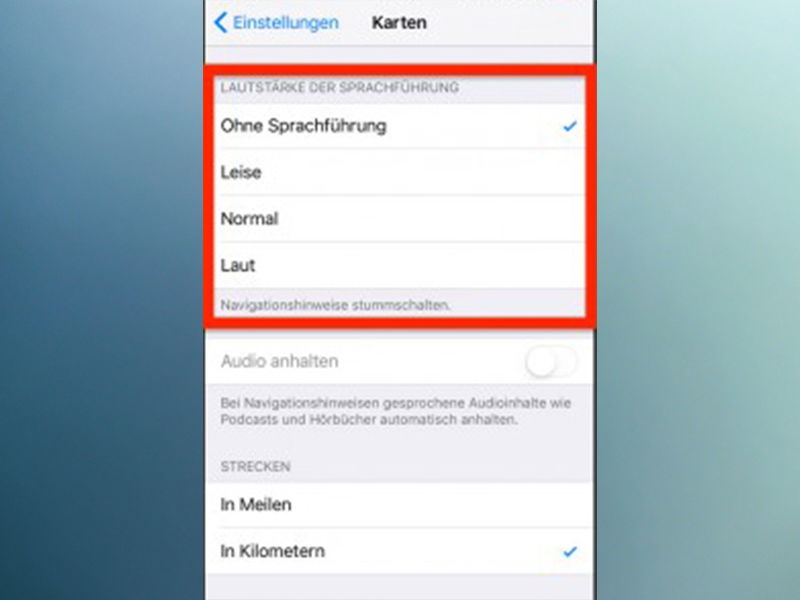

Wer ein eingeschränktes Sehvermögen hat und sich in einer Stadt trotzdem zurechtfinden möchte, kann damit leicht Schwierigkeiten haben. Einfacher wird die Navigation ab sofort mit der Microsoft-App Soundscape.




