

KI-Systeme erstellen längst nicht mehr nur Texte und Bilder, sondern auch Audios und Videos. Und die sind von echten Aufnahmen kaum noch zu unterscheiden. Was solche KI-Systeme heute schon können – und worauf wir achten müssen, um nicht auf Deepfakes hereinzufallen.
Deepfakes bestimmen jetzt schon die Schlagzeilen: Das gefälschte Taylor Swift-Video, das millionenfach geteilt wurde. Die Fake-Aufnahmen von vermeintlichen Politikern-Statements, die binnen Stunden viral gehen. Oder die perfekt imitierten Stimmen von CEOs, mit denen Kriminelle bereits Millionen erbeutet haben.
Die Qualität von KI-generierten Fakes hat 2025 einen Wendepunkt erreicht: Was früher Experten mit teurer Ausrüstung vorbehalten war, kann heute jeder mit dem Smartphone erstellen.
Künstliche Intelligenz durchdringt mittlerweile alle Medienformen: ChatGPT, Claude und Gemini erstellen auf Knopfdruck Texte in Profi-Qualität. Midjourney, DALL-E 3 und Stable Diffusion erzeugen fotorealistische Bilder. Doch die nächste Generation geht noch weiter: KI-Systeme erstellen heute täuschend echte Audio- und Videoinhalte.
Diese Technologien sind nicht mehr nur Tech-Giganten vorbehalten. Apps wie RunwayML, Synthesia oder D-ID machen Deepfake-Erstellung zum Kinderspiel – oft schon für wenige Euro im Monat. Die Demokratisierung dieser Technologie bringt enorme Chancen, aber auch beispiellose Risiken mit sich.

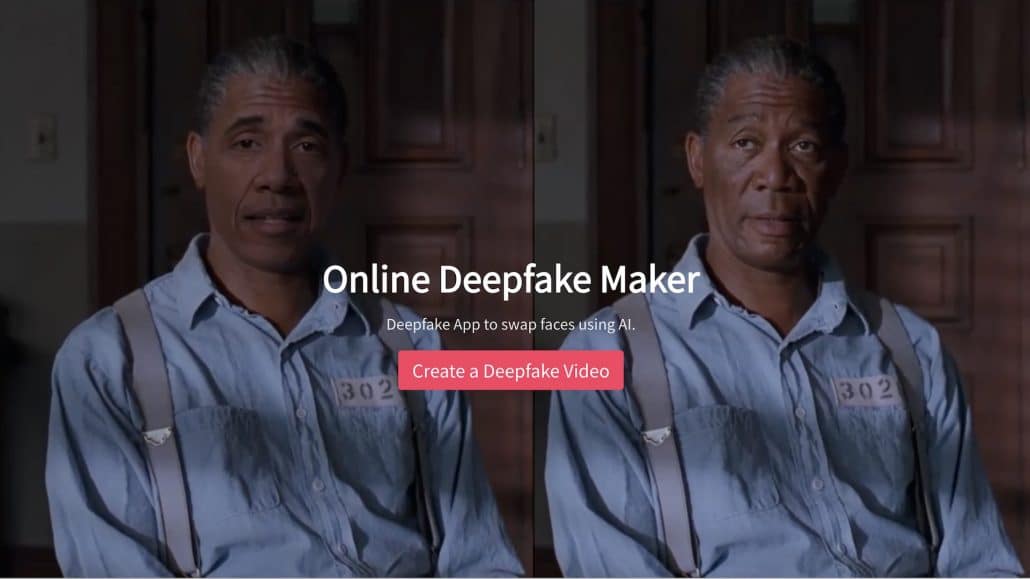
DeepFake
Voice Cloning: Wenn KI eure Stimme klont
Die Text-to-Speech-Revolution ist längst Realität geworden. Systeme wie ElevenLabs, Murf oder Speechify erstellen heute Sprachaufnahmen, die von menschlichen Stimmen praktisch nicht mehr zu unterscheiden sind. Das funktioniert mittlerweile auch auf Deutsch hervorragend – ein enormer Fortschritt seit 2023.
Die neuesten Modelle wie ElevenLabs Turbo v2.5 oder OpenAIs Advanced Voice Mode können Emotionen, Betonungen und sogar Dialekte perfekt nachahmen. Sie pausieren natürlich, variieren das Sprechtempo und fügen authentische Sprechgeräusche ein.
Besonders problematisch: Voice Cloning braucht heute nur noch wenige Sekunden Ausgangsmaterial. Ein kurzer Audioschnipsel aus einem Instagram-Video, einem Podcast oder Telefonat reicht aus, um eine komplette Stimme zu klonen. Meta hat mit Voicebox bereits demonstriert, dass sogar ein einziger Satz ausreichen kann.
Die Qualität ist erschreckend gut: Tests zeigen, dass selbst Familienmitglieder geklonte Stimmen ihrer Liebsten nicht erkennen. Kriminelle nutzen das bereits systematisch aus – der „Enkeltrick 2.0“ mit geklonten Kinderstimmen ist traurige Realität geworden.

Real-Time Deepfakes: Live-Manipulation wird Alltag
Die nächste Stufe sind Real-Time-Deepfakes: Systeme wie LivePortrait oder Real-Time Face Swap können live während Videocalls Gesichter austauschen oder die Lippenbewegungen anpassen. Was nach Science Fiction klingt, läuft bereits auf handelsüblichen Grafikkarten.
Unternehmen wie Synthesia haben „AI Avatars“ perfektioniert: Digitale Sprecher, die in über 130 Sprachen flüssig präsentieren können. Viele Unternehmen nutzen das bereits für Schulungsvideos oder Marketing – oft ohne zu kennzeichnen, dass KI im Spiel ist.
Doch die Technologie entwickelt sich rasant weiter: Runway ML Gen-3, Pika Labs oder Luma Dream Machine können mittlerweile aus einem einzigen Foto sprechende Videos generieren. Die Person muss nicht einmal kooperieren – ein Social Media-Profilbild reicht aus.

Deepfake: Das Foto ist ein Deepfake – die Audios von Olaf Scholz ebenso
Die dunkle Seite: Kriminelle Anwendungen nehmen zu
Die Kriminalstatistik zeigt einen alarmierenden Trend: Deepfake-Betrug ist 2025 um über 3000% gestiegen. Besonders perfide sind „CEO-Frauds“: Kriminelle klonen die Stimme von Geschäftsführern und weisen Mitarbeiter telefonisch zu Überweisungen an.
Ein Fall aus Hongkong machte Schlagzeilen: 25 Millionen Dollar Schaden durch ein gefälschtes Video-Meeting mit dem CFO. Alle Teilnehmer waren Deepfakes – nur das Opfer war echt. Solche Angriffe werden zur neuen Normalität.
Ebenso problematisch: Non-Consensual Deepfakes, also gefälschte intime Videos ohne Zustimmung der Betroffenen. Plattformen wie Telegram werden regelrecht geflutet mit solchen Inhalten. Die psychischen Schäden für Betroffene sind verheerend.
Das BSI warnt eindringlich vor dieser Entwicklung. Gerhard Schabhüser erklärt: „Wir sehen eine professionelle Kriminalisierung von Deepfake-Technologien. Die Täter agieren international und nutzen KI-as-a-Service-Plattformen.“
Gegenmaßnahmen: Der Kampf um digitale Authentizität
Die Industrie reagiert mit verschiedenen Ansätzen: Adobe hat Content Credentials entwickelt, eine Art digitalen Fingerabdruck für Medieninhalte. Intel bietet mit FakeCatcher ein System zur Deepfake-Erkennung. Auch Microsoft, Google und Meta investieren Milliarden in Detection-Technologien.
Doch es ist ein Wettrüsten: Während Detection-Systeme besser werden, entwickeln sich auch die Fälschungstechnologien weiter. Adversarial AI-Systeme können gezielt Schwächen in Erkennungssoftware ausnutzen.
Ein vielversprechender Ansatz sind Blockchain-basierte Verifikationssysteme. Jedes authentische Video oder Audio erhält einen kryptographischen Beweis seiner Echtheit. Ohne diesen „Authenticity Token“ gilt Content als potentiell gefälscht.
FaceSwap
Praktische Tipps: So schützt ihr euch vor Deepfakes
Bis bessere technische Lösungen verfügbar sind, müssen wir unsere digitale Medienkompetenz schärfen:
Bei Audios achten auf:
– Unnatürliche Atmung oder fehlende Nebengeräusche
– Zu perfekte Aussprache ohne regionale Färbung
– Monotone Betonung bei emotionalen Inhalten
– Inkonsistente Sprachgeschwindigkeit
Bei Videos prüfen:
– Lippensynchronität genau beobachten
– Augenbewegungen und Blinzeln kontrollieren
– Haarlinien und Ohrränder auf Unschärfen untersuchen
– Schatten und Lichtverhältnisse kritisch betrachten
Generelle Vorsichtsmaßnahmen:
– Ungewöhnliche Anfragen telefonisch rückversichern
– Bei verdächtigen Inhalten Quellencheck durchführen
– Reverse-Image-Search bei auffälligen Fotos nutzen
– Im Zweifel lieber einmal zu viel nachfragen
Ausblick: Leben in der Post-Truth-Ära
Wir stehen am Beginn einer Ära, in der die Unterscheidung zwischen echt und künstlich immer schwieriger wird. Das EU AI Act und ähnliche Regulierungen weltweit versuchen, die schlimmsten Auswüchse einzudämmen. Doch Technologie entwickelt sich schneller als Gesetze.
Experten prophezeien, dass wir bis 2027 einen „Authenticity Crisis Point“ erreichen werden: Der Punkt, an dem Deepfakes so perfekt sind, dass sie auch mit bester Technologie nicht mehr zu erkennen sind.
Die Lösung liegt nicht nur in besserer Technologie, sondern auch in einem kulturellen Wandel: Wir müssen lernen, digitale Inhalte grundsätzlich kritischer zu hinterfragen. Das gesunde Misstrauen, das unsere Großeltern gegenüber allem Gedruckten hatten, brauchen wir heute für alles Digitale.
In dieser neuen Welt wird nicht die Frage sein, ob wir Deepfakes begegnen – sondern wie gut wir darauf vorbereitet sind.
Zuletzt aktualisiert am 18.02.2026



